
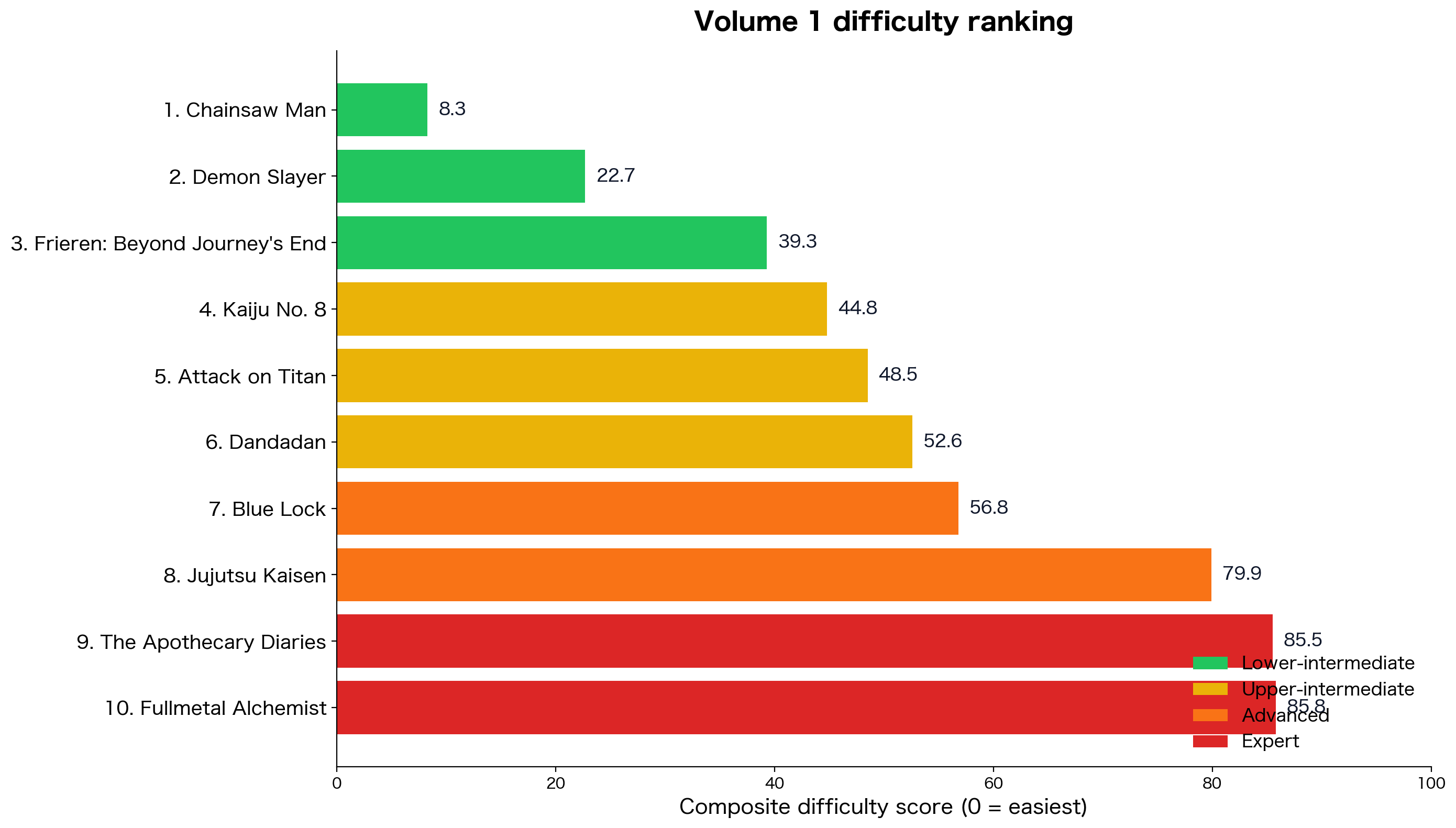
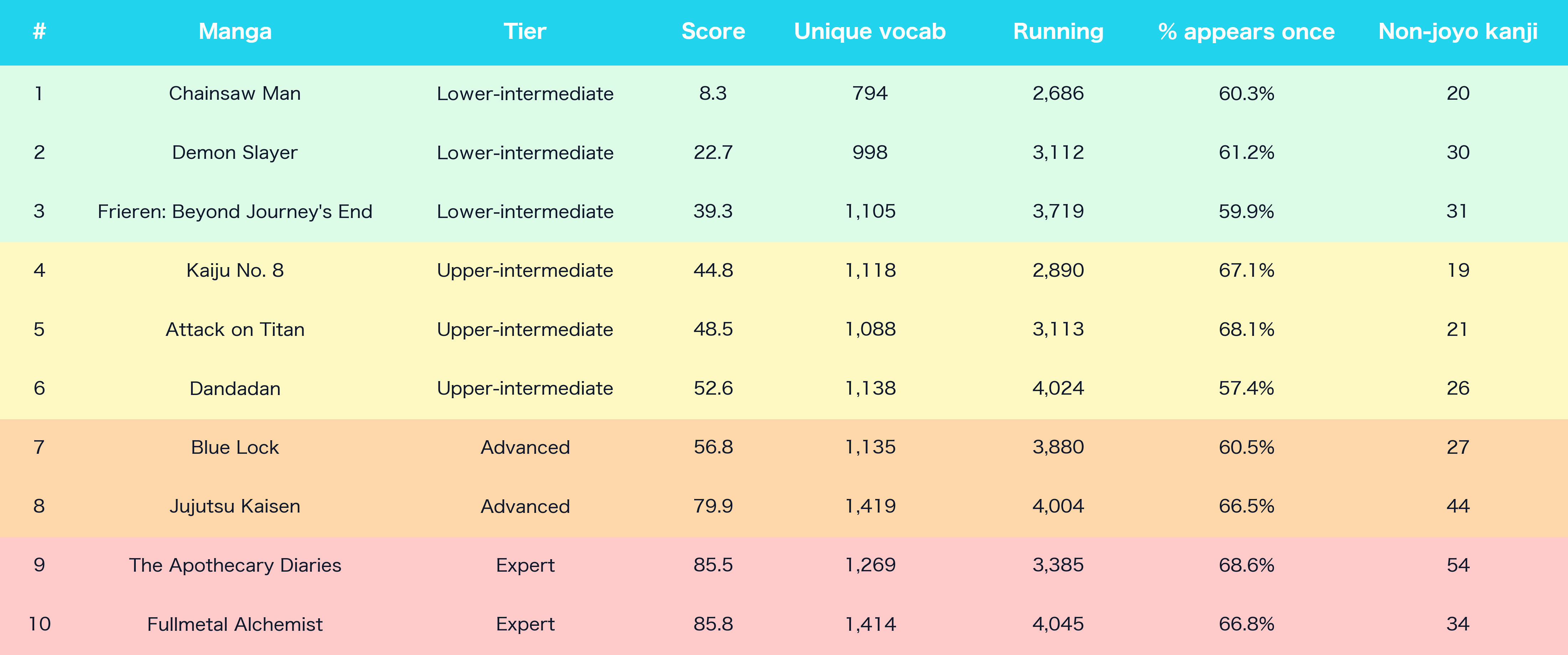
We measured volume 1 of ten popular manga against the JLPT N5 to N1 lists and the 2,136-character joyo set. Chainsaw Man is the easiest. Fullmetal Alchemist and The Apothecary Diaries are the hardest. The full ranking is below.
But the ranking is not the most interesting thing in this article. The most interesting thing is what happens when you stop reading one manga and start reading several.
In any single volume, 63% of the unique vocabulary appears exactly once. One encounter, no repeats, gone. That is the long tail you have heard everyone complain about. It is why volume 1 of anything feels brutal.
Now read all ten volumes. The single-occurrence share drops to 55%. Read 4,000 words, the share drops a third of the way there. Read 10,000 words, you are most of the way down. The long tail does not disappear. But every volume you add chips at it. The work compounds across books in a way it cannot compound inside one book.
The lazy reader who jumps between five different series is not procrastinating. They are accidentally building the most efficient vocabulary base of anyone in the room.
Every number in this article comes from Ashiba's production corpus, measured against the official N5 to N1 JLPT vocabulary lists and the 2,136-character joyo kanji set. Last measured 2026-05-01.
The ranking
Ten volume-1 manga, ranked from easiest to hardest by a composite difficulty score (0 = easiest, 100 = hardest). The score combines five things, each normalized across the ten volumes: total running tokens (workload), unique vocabulary (breadth), non-joyo kanji count, the share of running tokens outside the JLPT framework (jargon density), and the in-volume long-tail share (in-book repetition).
The four tiers
Lower-intermediate (rank 1 to 3): Chainsaw Man, Demon Slayer, Frieren. The easiest entry points if you have finished Genki II. Chainsaw Man is the easiest book in the corpus by a wide margin. It has the smallest vocabulary (794 unique words), the lightest workload (2,686 running tokens), the lowest jargon density (28% of running tokens outside JLPT), and only 20 non-joyo kanji. Furigana on every kanji. The pain is real but contained. If you are picking your first manga, start here.
Upper-intermediate (rank 4 to 6): Kaiju No. 8, Attack on Titan, Dandadan. A step up. The vocabulary breadth is wider (1,088 to 1,138 unique), the unlisted bucket is in the 30 to 33% range, and the long tail bites harder. Attack on Titan has the heaviest institutional vocabulary domain (調査兵団, 駐屯兵団, 立体機動装置). Dandadan stacks occult-spirit terminology on sci-fi alien terminology on slangy teenage-girl voice in the same chapter. Kaiju No. 8 is mostly a military-procedural register with a smaller running-token count than the other two.
Advanced (rank 7 to 8): Blue Lock, Jujutsu Kaisen. Blue Lock's entire vocabulary domain is soccer-coaching plus self-help-flavored egoism: 33% of its running tokens are outside JLPT, and you will see サッカー (67 times) and ストライカー (31 times) become familiar fast. Jujutsu Kaisen jumps to 1,419 unique words and 44 non-joyo kanji. The fights are easy. The exposition is not: 225 unique words sit at JLPT N1 because Gege Akutami invented the curse-vocabulary system from scratch.
Expert (rank 9 to 10): The Apothecary Diaries, Fullmetal Alchemist. Apothecary Diaries has the heaviest unlisted-bucket share in the corpus (35% of running tokens) because the entire setting runs on imperial-court vocabulary, herbalist vocabulary, and consort hierarchy terms. Fullmetal Alchemist has the second-largest unique-vocabulary count (1,414) and 34 non-joyo kanji. Both are great books. Neither is your first one.
The JLPT mix per volume
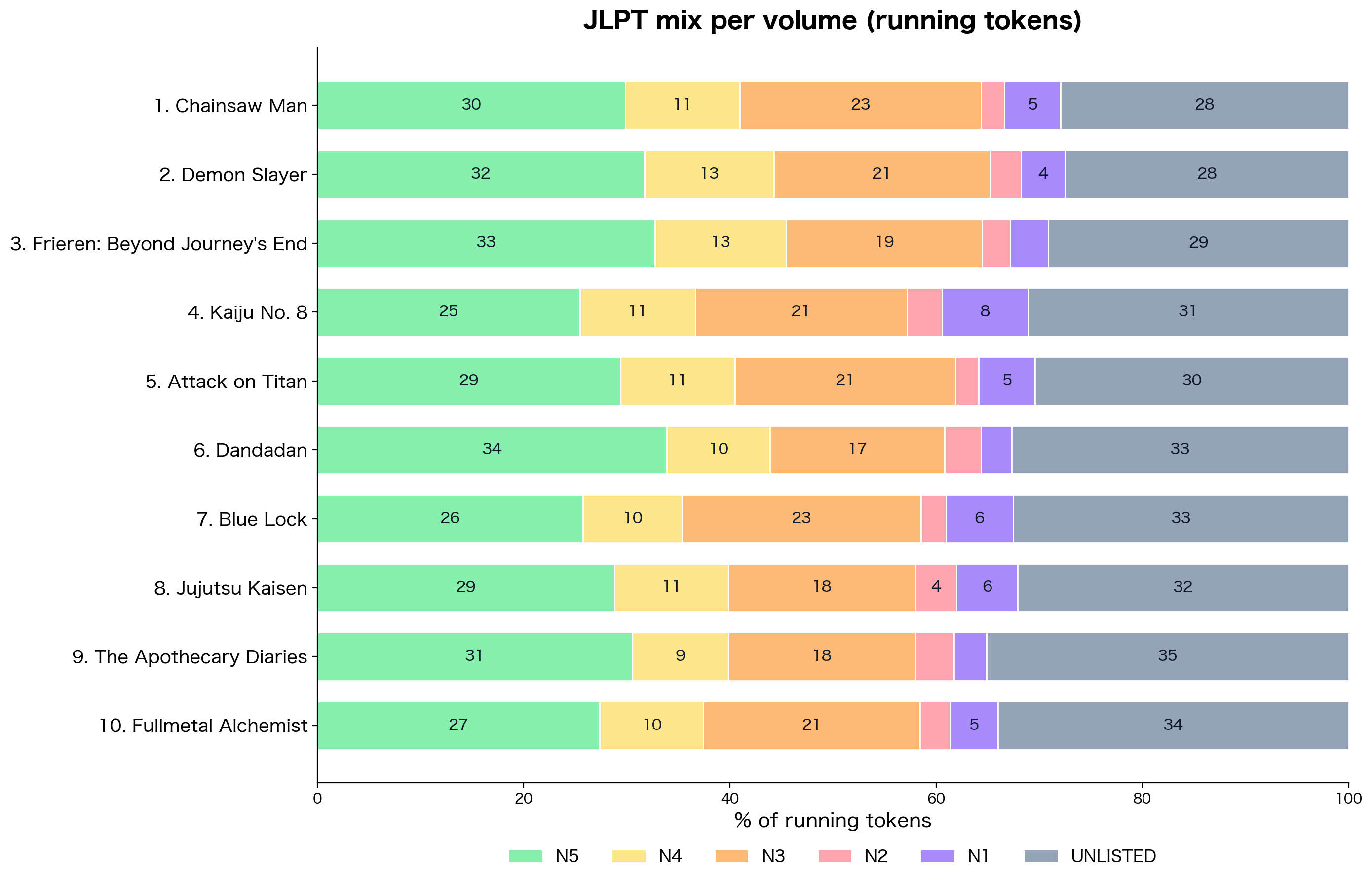
Two patterns in this chart. First: N5+N4 covers roughly 40% of running tokens in every volume. The grammar particles, the basic verbs (する, なる, 言う, 行く, 見る), the everyday connectives. That is the floor that does not change between Chainsaw Man and Apothecary Diaries. Second: the unlisted bucket grows as the difficulty grows. 28% in Chainsaw Man. 35% in Apothecary Diaries. The difficulty is not coming from harder JLPT levels. It is coming from the world-specific vocabulary domain.
Stop optimizing your starting volume
I just gave you the data to optimize. Now I want to argue against using it.
The rankings tell you which book has the lightest vocabulary load. They do not tell you which book you will finish. Those are different questions, and only the second one matters.
The reader who picks Chainsaw Man because it is easiest, but does not actually want to read Chainsaw Man, will quit on chapter 3. The reader who picks Apothecary Diaries because they have watched the anime four times and love Maomao, will get through volume 1 even though the vocabulary is the heaviest in the corpus. Motivation outvotes vocabulary load every time.
This is the trap I see learners fall into constantly. They want a stepping stone. They scan a list like the one above, pick the easiest book, and treat the choice as a strategic optimization. It feels responsible. It is fear in a costume. Boredom is the deadliest of the three demons because it disguises itself as strategy. You picked the easy one and then you put it down because you did not actually want to read it. You got beaten by your own optimization.
Use the ranking the other way. If two books pull you equally, the difficulty score is the tiebreaker. If one book pulls you and another book is easier, read the one that pulls you. Hard stories you love beat easy stories you do not.
The cross-volume long-tail effect
Now the part of this analysis that surprised me.
Take any single volume. Count the unique words. Count how many appear exactly once. Across our ten volumes, the average is 63%. About two thirds of the words you meet in volume 1 do not show up again in volume 1.
That single number is the entire reason vocabulary acquisition feels so brutal in your first book. You look up a word, you understand the sentence, the word never repeats, and 50 pages later you cannot remember it. You did not see it enough times in this book to learn it. The book did not give you the reps.
Now do the same calculation across pooled volumes. Treat all ten volume-1s as one giant text. Count unique words across the pool. Count how many appear exactly once across the pool.
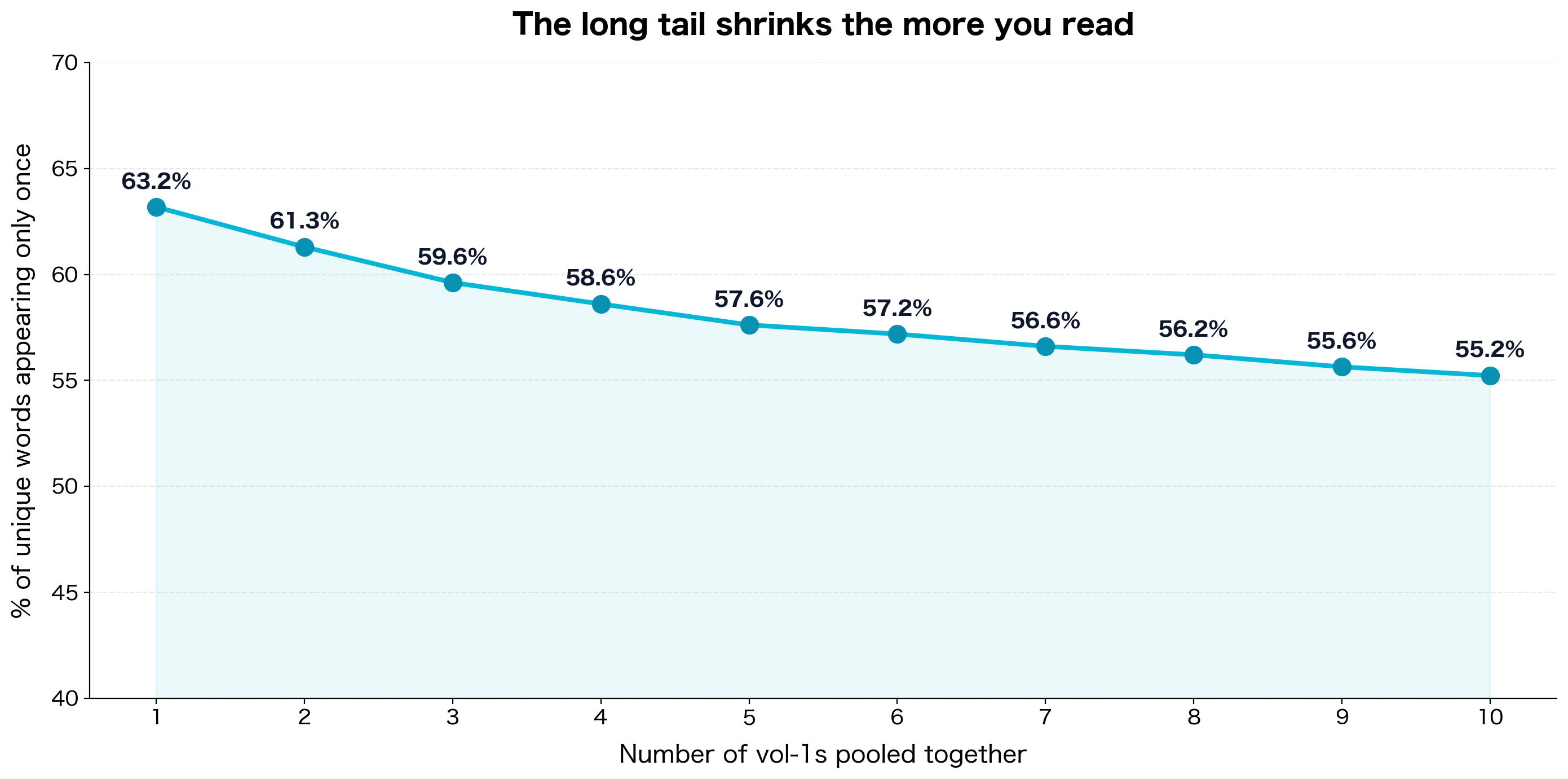
The number drops from 63.2% to 55.2% as you pool from one volume to ten. The share of dead-end words shrinks by eight percentage points. In raw counts: across the ten pooled volumes there are 6,241 unique words, 3,447 of which still appear only once. In a single volume, roughly 700 to 900 of the volume's words appear only once. Reading more books does not eliminate the long tail. It compresses it.
Where do the eight points come from? Words that appear once in volume A and once in volume B are no longer single-occurrence in the pool. Across the ten volumes, 482 words appear in five or more series, and 72 words appear in all ten. The all-ten-series club is exactly what you would expect: そんな, です, でも, も, 行く, 事, 見る, もう, 今, 言う, 所, plus the core particles. Those words you will see often even reading just one book. But the next layer down (words shared across three, four, five series) is what compounding actually buys you. Each new manga you start is a new chance to convert a single-occurrence word in book A into a repeated-occurrence word across your reading life.
This is also why the people who read very slowly for a long time across many series end up with absurdly large recognition vocabularies. They are not memorizing. They are exposing themselves to more shared head-of-the-distribution words while the long tail proportionally compresses on every new book.
The practical takeaway
If you only ever read one manga, you will spend most of your effort on words that do not repeat. 63% of what you look up in volume 1 you will not see again in volume 1. That ratio does not improve until you broaden.
Broadening is more efficient than deepening, up to a point. Two volumes of two different series produces a denser repeat-vocabulary base than four volumes of one series, because you pull from different word-frequency distributions and the high-frequency words start cross-matching. The ratio of useful reps to dead-end lookups goes up.
The same logic eventually flips inside a series. Once you are 4 to 5 volumes deep in a single series, the world-specific vocabulary stops being long tail. 呪い in Jujutsu Kaisen, 巨人 in Attack on Titan, ストライカー in Blue Lock all become repeating head-of-distribution words. Series depth becomes efficient again at that point. The most efficient pattern is breadth early, depth later.
Pre-studying chapter vocabulary is the only intervention that actually changes the single-volume long-tail problem. The reason ASHIBA exists. If 60% of the words you meet appear once, looking each one up mid-page costs you the story. Move the lookups out of the story. Put them into focused practice before you read the chapter. The same reps, ordered correctly. The story stays intact.
Methodology
Every number above was computed from approved panel chunks for each volume in Ashiba's production database. Per-volume uniques are deduplicated by target id. Cross-volume pooling is by lemma key (kanji form + hiragana form) so the same word in different volumes counts as the same word.
JLPT levels were assigned by matching against the official N5 to N1 vocabulary lists. Words not on any list are marked "unlisted" (proper nouns, manga-specific jargon, slang, onomatopoeia). The composite difficulty score is a weighted sum of five normalized components: running tokens (0.25), non-joyo kanji count (0.10), unlisted-share-of-running (0.30), in-volume long-tail share (0.25), unique vocabulary (0.10). Weights chosen to emphasize jargon density and total workload, the two factors that most predict whether a learner finishes.
Read more
Per-volume deep dives, with full JLPT distribution, kanji analysis, and panel breakdowns:
- Chainsaw Man volume 1: rank 1, the easiest entry point.
- Demon Slayer volume 1: rank 2, furigana everywhere.
- Frieren volume 1: rank 3, the lightest fantasy register.
- Kaiju No. 8 volume 1: rank 4, military-procedural domain.
- Attack on Titan volume 1: rank 5, institutional vocabulary.
- Dandadan volume 1: rank 6, register collision.
- Blue Lock volume 1: rank 7, soccer-and-egoism domain.
- Jujutsu Kaisen volume 1: rank 8, curse-vocabulary system.
- The Apothecary Diaries volume 1: rank 9, court vocabulary.
- Fullmetal Alchemist volume 1: rank 10, alchemy-and-philosophy.
Related editorial:
- Stop Studying Japanese at Your Level: why hard stories you love beat easy stories you do not.
- Why You'll Want to Quit Japanese: the three demons (fear, pain, boredom) and how to beat them.
- The Fastest Way to Learn Japanese: activity-atrophy cycle and minimum viable effort.
ASHIBA pre-teaches the chapter vocabulary for every series ranked above so the long tail moves out of your reading and into focused practice before you open the book.
Try ASHIBA